Columnar Database Concept in TuringDB
Overview
Traditional graph databases such as Neo4J or MemGraph typically execute queries by processing one node or one edge at a time. This row-by-row processing model, known as the Volcano model, limits performance in analytical workloads due to its inherently sequential execution model. TuringDB departs from this classical architecture by adopting a column-oriented, vectorized processing model, enabling high-performance analytics on large-scale graphs by operating on chunks of nodes and edges simultaneously. This design opens the door to modern hardware optimizations like SIMD vectorisation, cache locality, and fine-grained parallelism, significantly outperforming traditional approaches on analytics tasks.Why the Volcano Model Is Limiting Modern Analytics
The classical Volcano model of query execution, introduced in early relational database systems, follows a pull-based, tuple-at-a-time execution model. Each operator in a query pipeline calls its child operator to retrieve the next tuple, processes it, and passes the result upward. This results in a sequential, record-by-record evaluation that fails to leverage the full power of contemporary processors. As noted in seminal research Boncz et al., 2005, this model lacks natural concurrency and inhibits performance by preventing vectorised execution. That is, the query engine cannot take advantage of modern processor instructions (SIMD: Single Instruction, Multiple Data) which can apply the same operation to multiple data elements simultaneously.Enter Columnar Storage and Execution
Columnar databases change the paradigm. Instead of storing data row-by-row, they store each attribute (or property) in a separate column, represented as a contiguous array in memory. This structure naturally aligns with analytical query patterns.Benefits of Columnar Layout
- Cache locality: Analytical queries often focus on a subset of attributes (e.g., filtering by degree, computing average weight). With columnar storage, only relevant columns are scanned, improving cache efficiency and reducing memory bandwidth usage.
- Vectorisation: Columns are stored as arrays, which means operations like
SUM,AVG, orFILTERcan be implemented as tight, SIMD-optimized loops over contiguous memory blocks. - Parallelism: Columns can be chunked and distributed across threads or cores, enabling highly parallel execution without the need for complex coordination.
AVG(price) can be executed as a single vectorised pass over the price column, without touching the customer_id values.
For a practical overview of the differences, see TigerData’s comparison of column vs row-oriented databases.
Columnar Execution in our Graph Database
Despite the advantages, graph databases have largely remained tied to the Volcano model. Systems like Neo4J and MemGraph still process graph elements one-by-one, iterating through edges and nodes in a sequential and pointer-chasing fashion. This design significantly limits performance for:- Deep, multi-hop traversals
- Graph-based aggregations (e.g., finding most connected nodes)
- Real-time analytical dashboards
- AI pipelines with graph-based feature extraction
TuringDB: A Column-Oriented Graph Database Engine
TuringDB brings the power of columnar processing to graph data. Instead of row-by-row traversal, TuringDB uses a streaming, columnar query pipeline that operates on vectors (or chunks) of nodes and edges. This is analogous to how column-store analytical databases operate, but adapted to the structural and relational richness of graphs.What This Enables
- Massive vectorised query execution across node/edge properties
- SIMD acceleration for graph filters, joins, and traversals
- Parallel scheduling of analytical workloads on high-throughput systems
- Fast multi-hop reasoning, without paying the performance penalty of pointer-based iteration
References
- Boncz, Peter A., et al. (2005). MonetDB/X100: Hyper-pipelining Query Execution. CIDR 2005
- TigerData. Columnar Databases vs Row-Oriented Databases: Which to Choose? Read here
Streaming Execution Engine
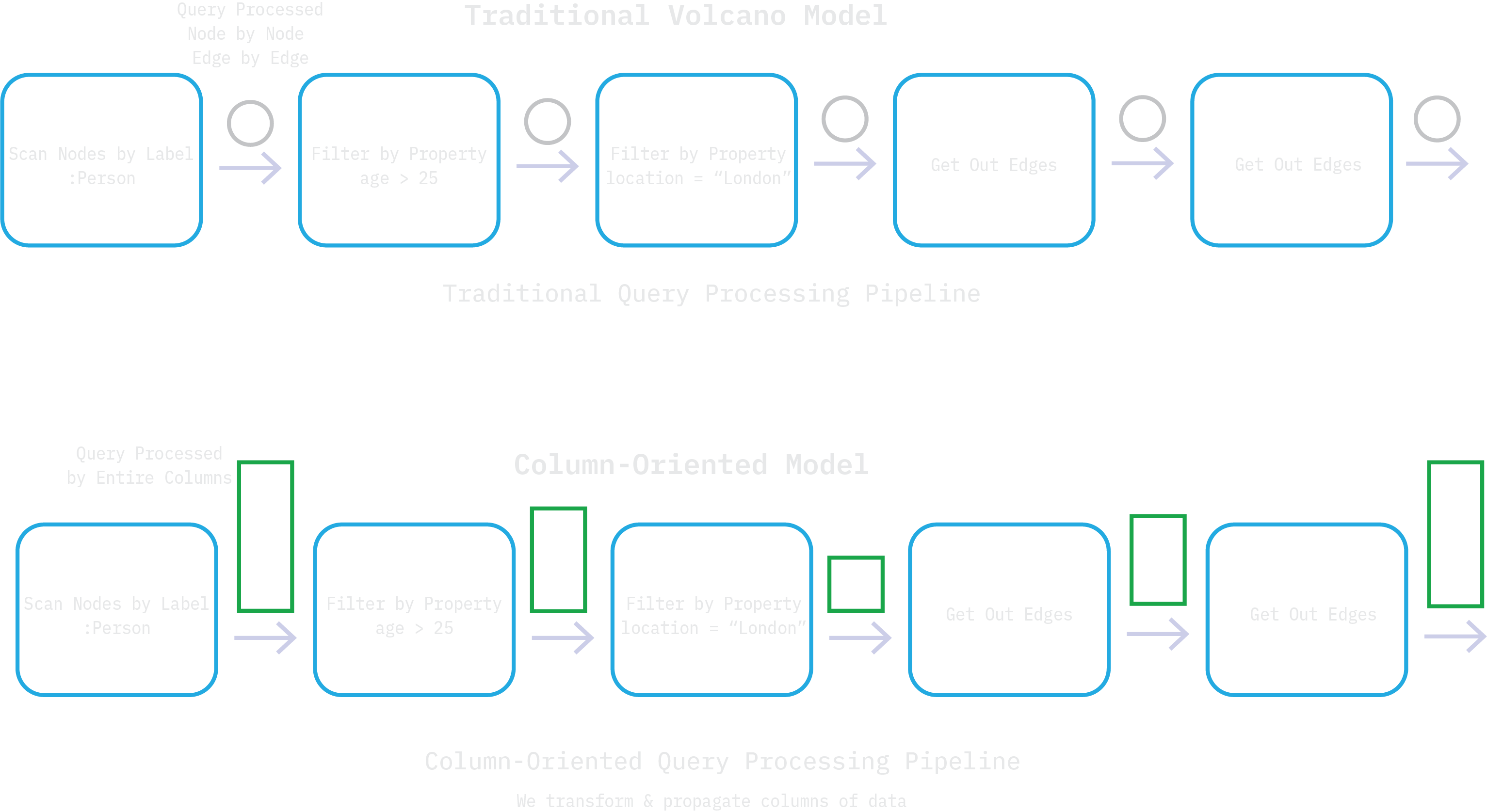
At the core of TuringDB’s performance lies its Streaming Execution Engine, a query execution pipeline purpose-built for modern hardware and analytical workloads. Unlike classical graph engines (e.g., Neo4J, MemGraph) that follow a Volcano model, processing one node or edge at a time, TuringDB introduces a columnar, chunk-based, streaming execution pipeline that operates on arrays of graph data.Traditional vs Streaming: A Quick Recap
Traditional Volcano Model
- Row-oriented and implies pointer-chasing for graph databases
- One node/edge at a time
- Poor CPU cache locality
- Hard to parallelize
- No vectorisation
TuringDB’s Columnar Streaming Model
- Works on columns of nodes or edges (stored in DataParts)
- Filters, joins, and traversals are applied to batches/chunks of data
- Leverages SIMD vectorisation
- Easily parallelized across CPU cores
- Data locality ensures fast memory access
How It Works: DataParts + Column Flow
TuringDB stores all nodes and edges in DataParts, which are:- Immutable
- Column-oriented (arrays of nodes, arrays of edges)
- Optimized for scanning and transformation
Example:
SCAN NODES BY LABEL "Person"→ Returns a column of node IDsFILTER BY PROPERTY age > 25→ Produces a smaller columnFILTER BY PROPERTY location = "California"→ Another transformationGET OUT EDGES→ Generates a column of edges to traverse next
Why Hasn’t This Been Done in Graph DBs Before?
Graphs are arbitrarily connected. In classical designs:- Each node/edge is stored as a distinct object
- Memory is scattered and pointer-chasing is expensive on modern hardware
- Collecting or grouping nodes and edges into columns is not obvious or costly
- Being focused on analytical workloads with batch writes allows is to consider contiguous array-based storage of nodes and edges. This is difficult for traditional systems heavily focused on writes.
The TuringDB Solution
TuringDB reintroduces contiguity into graph systems through:The DataPart System
Each DataPart contains:- An array of nodes
- An array of out edges
- An array of in edges
- Fall back on the proven model of column processing, just like relational database systems
- Achieve vectorisation and cache-local execution, on graphs
- Process millions of nodes and edges in milliseconds
Summary
| Feature | Traditional Graph DBs | TuringDB Streaming Engine |
|---|---|---|
| Execution model | Tuple-at-a-time (Volcano) | Columnar Streaming |
| Memory access | Scattered | Contiguous (DataParts) |
| SIMD/vectorisation | ❌ Limited | ✅ Native |
| Parallelism | Manual or limited | ✅ Chunk-based & automatic |
| Read performance | 🐢 Slow on scale | ⚡ Millisecond-level |